Introduction à l’utilisation des transformers avec Hugging Face
Comprendre les transformateurs et exploiter leur puissance pour résoudre des problèmes concrets.

Introduction
Si je devais expliquer le principe des tranformers à un enfant de 6 ans, voici ce que je dirais:
“Imagine que tu as une boîte de jouets devant toi. Certains jouets te plaisent plus que d’autres. Maintenant, imagine que tu as une petite lampe magique qui peut briller plus ou moins fort sur chaque jouet. Les jouets que tu aimes le plus reçoivent la lumière la plus brillante, et ceux que tu aimes le moins reçoivent une lumière plus faible.
Le mécanisme d’attention, c’est comme cette lampe magique. Quand une machine essaie de comprendre une histoire ou une phrase, elle utilise ce mécanisme pour décider quels mots (ou “jouets”) sont les plus importants à un moment donné. Elle “éclaire” ces mots plus que les autres pour mieux comprendre l’histoire.”
Cependant, si le principe en révolutionnairement simple, il devient difficile d’aller plus loin sans se retrousser les “neurones”. Le challenge ici est de trouver le moyen de donner la capacité à des systèmes automatisée de trouver les “jouets” ou mots sans aide même d’un enfant de 5 ans. La technologie qui a permis cela est la technologie des transformers.
Les transformers sont des modèles de réseaux de neurones artificiels qui utilisent des mécanismes d’attention pour traiter des séquences de données. Ils ont été introduits en 2017 par Vaswani et al. dans l’article “Attention is all you need” et ont révolutionné le domaine du traitement automatique du langage naturel (TALN).
Les transformers sont particulièrement adaptés pour les tâches de compréhension et de génération de texte, comme la traduction automatique, la résumé automatique, la réponse aux questions ou la création de contenu. Ils sont à la base des modèles de langage pré-entraînés (LLM ou Large Language Model) qui exploitent de grandes quantités de données textuelles pour apprendre des représentations sémantiques et syntaxiques.
Dans cet article, nous allons présenter les principes de fonctionnement des transformers, leurs avantages et leurs limites, ainsi que quelques exemples d’applications pour les LLM.
Les origines
Le papier “Attention is All You Need” introduit le modèle Transformer, qui est devenu la base de nombreux modèles de traitement du langage naturel modernes (tel que ChatGPT). Le modèle Transformer repose entièrement sur des mécanismes d’attention pour capter des dépendances globales (entre les mots), quel que soit leur éloignement dans le texte. Contrairement aux architectures précédentes qui utilisaient des réseaux de neurones récurrents (RNN) ou des convolutions, le Transformer évite leur séquentialité (inhérente aux RNN et aux convolutions) en utilisant uniquement l’attention. Cela permet d’obtenir des gains significatifs en termes de performance et de vitesse de formation.
Dans l’architecture des modèles basés sur l’attention, comme le Transformer, le mécanisme d’attention permet à la machine de pondérer l’importance relative de chaque mot ou élément d’une séquence par rapport à un autre en procédant comme suit:
- Pondération des mots : L’attention détermine à quel point chaque mot d’une phrase est important par rapport à un autre mot. Par exemple, dans la phrase “Le chat dort sur le canapé”, si nous nous concentrons sur le mot “dort”, l’attention pourrait donner plus d’importance aux mots “chat” et “canapé” car ils sont directement liés à l’action de dormir.
- Calcul des scores d’attention : Pour chaque mot, un score est calculé en fonction de sa relation avec les autres mots. Ces scores déterminent l’importance relative de chaque mot.
- Application des poids d’attention : Les scores d’attention sont utilisés pour pondérer les représentations (ou vecteurs) des mots. Les mots avec des scores d’attention élevés auront une influence plus importante sur la représentation finale.
- Aggrégation des informations : Les représentations pondérées des mots sont ensuite combinées pour produire une nouvelle représentation qui prend en compte l’importance relative de chaque mot.
- Flexibilité : L’attention permet au modèle de se concentrer sur des parties spécifiques de la séquence d’entrée, quelle que soit leur position. Cela est particulièrement utile pour comprendre les relations à longue distance entre les mots ou les éléments d’une séquence.
L’attention permet donc à la machine de “zoomer” sur les parties les plus pertinentes d’une séquence tout en “dézoomant” ou en donnant moins d’importance aux parties moins pertinentes. Cela aide le modèle à comprendre les dépendances et les relations entre les mots, ce qui améliore sa capacité à traiter et à générer du texte de manière globale et directe.
Architecture des transformers:
Avec une meilleure compréhension de ce que c’est que l’attention d’un point de vue numérique, on peut désormais décrire brièvement les composantes principales de l’architecture du modèle proposé par le papier “Attention is All you need”. Pour résumer l’architecture du modèle transformer est composé de:
- Mécanisme d’Attention Multi-Têtes: Au lieu d’avoir une seule série de poids d’attention, le Transformer utilise plusieurs séries, permettant au modèle de se concentrer sur différentes parties du texte simultanément.
- Réseaux de Feed-Forward Positionnels: Chaque position dans l’entrée a un réseau feed-forward distinct, qui est identique en termes de paramètres. Ces réseaux permettent de traiter les informations positionnelles, car le modèle n’a pas de notion d’ordre inhérente.
- Encodage Positionnel: Comme le modèle ne possède pas de mécanisme séquentiel, des informations positionnelles sont ajoutées aux entrées pour donner une notion d’ordre aux mots.
- Normalisation des Couches: Après chaque sous-couche (attention ou feed-forward), une normalisation est effectuée pour stabiliser les activations.
- Empilement des Encodeurs et des Décodeurs: L’architecture complète est composée d’un certain nombre d’encodeurs et de décodeurs empilés. Chaque encodeur réalise l’auto-attention et le traitement feed-forward, tandis que chaque décodeur réalise l’auto-attention, l’attention multi-têtes sur la sortie de l’encodeur, et le traitement feed-forward.
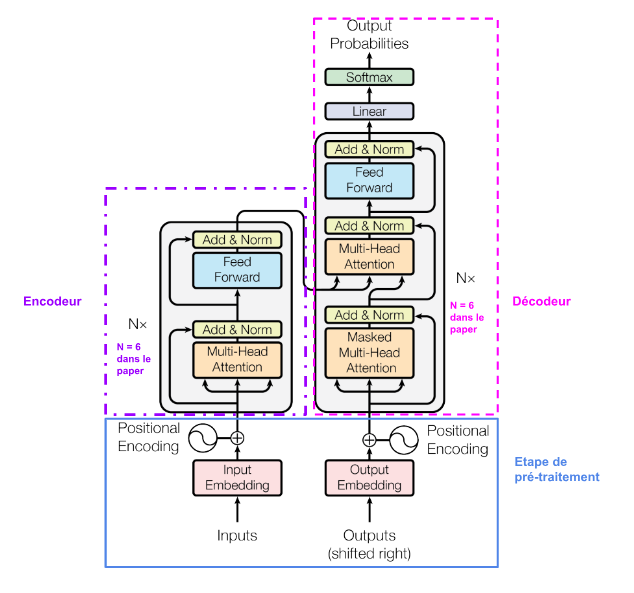
Rôle des composantes:
- Attention Multi-Têtes: Permet au modèle de se concentrer sur différentes parties du texte simultanément, capturant ainsi divers types de relations.
- Réseaux de Feed-Forward Positionnels: Traite les informations à chaque position de manière indépendante, permettant une parallélisation efficace.
- Encodage Positionnel: Donne une notion d’ordre et de position aux mots dans la séquence.
- Normalisation des Couches: Stabilise les activations et facilite l’apprentissage.
- Encodeurs et Décodeurs: Les encodeurs traitent l’entrée, tandis que les décodeurs génèrent la sortie, en utilisant à la fois l’auto-attention et l’attention sur la sortie de l’encodeur.
Au centre du mécanisme d’attention:
Prenons l’exemple d’une phrase en français que l’on souhaiterait traduire en Anglais. Le jeu de données consisterait donc en un ensemble de phrases en Français avec leurs correspondances en Anglais. Si l’on retrace le voyage de la donnée au travers du mécanisùe d’attention, voici ce qu’il se passe:
- Embedding : Les mots de la séquence d’entrée sont d’abord convertis en vecteurs numériques, appelés embeddings. Ces embeddings capturent la signification sémantique des mots.
- Encodage Positionnel : Comme le Transformer n’a pas de notion d’ordre séquentiel, un encodage positionnel est ajouté aux embeddings pour indiquer la position de chaque mot dans la séquence.
- Calcul des Scores d’Attention :
- Pour chaque mot, trois vecteurs sont calculés : la clé (Key), la valeur (Value) et la requête (Query).
- Le score d’attention est calculé en prenant le produit scalaire de la requête d’un mot avec la clé de tous les autres mots, puis en appliquant une fonction softmax pour obtenir des poids d’attention.
La requête, la valeur et la clé sont des concepts utilisés dans le mécanisme d’attention pour calculer les poids d’attention, qui indiquent l’importance relative de chaque élément de la séquence. On peut les comparer à un système de recherche, où :
- La requête (Q) est l’information que l’on cherche à compléter ou à enrichir. Par exemple, si on veut traduire le mot “chat” en anglais, la requête est le vecteur (on parle d’embedding) qui représente le mot “chat” dans l’espace sémantique du modèle. La requête représente le mot ou le contexte que nous examinons actuellement.
- La clé (K) est l’information qui permet d’identifier un élément de la séquence. Par exemple, si on a une phrase en anglais comme “The cat is on the table”, la clé est le vecteur qui représente chaque mot de la phrase dans l’espace sémantique du modèle. La clé sert à évaluer la pertinence ou l’importance d’un mot par rapport à une requête donnée.
- La valeur (V) est l’information que l’on veut récupérer ou utiliser. Par exemple, si on a une phrase en français comme “Le chat est sur la table”, la valeur est le vecteur qui représente chaque mot de la phrase dans l’espace sémantique du modèle (l’ensemble des mots formant donc une matrice).
Ces trois matrices sont obtenues en multipliant l’embedding du mot par trois matrices de poids distinctes (d’où les couches linéaires sur le graphique ci-dessous), qui sont apprises pendant l’entraînement du modèle. Ces matrices de poids transforment l’embedding original en trois représentations différentes pour les besoins du mécanisme d’attention.
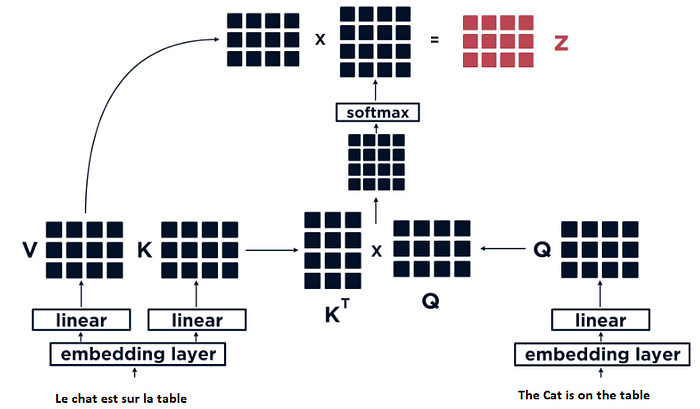
- Pondération des Vecteurs : Le mécanisme d’attention calcule ensuite une similarité entre la requête et chaque clé, et utilise cette similarité pour pondérer les valeurs correspondantes. Le résultat est une combinaison linéaire des valeurs pondérées par les poids d’attention, qui représente l’information recherchée par la requête. Les poids d’attention sont utilisés pour pondérer les vecteurs “Value”. Si un mot a un poids d’attention élevé par rapport à un autre mot, sa représentation (vecteur “Value”) aura une influence plus importante. Par exemple, si on veut traduire le mot “chat” en anglais, le mécanisme d’attention va comparer le vecteur du mot “chat” avec les vecteurs des mots anglais de la phrase “The cat is on the table”, et trouver que le mot le plus similaire est “cat”. Il va alors attribuer un poids d’attention élevé au vecteur du mot “cat”, et des poids d’attention faibles ou nuls aux autres vecteurs. Il va ensuite sommer les vecteurs des mots français de la phrase “Le chat est sur la table”, pondérés par les poids d’attention, et obtenir un vecteur qui représente le mot “cat” en français.
- Aggrégation : Les vecteurs “Value” pondérés sont sommés pour produire une seule représentation pour chaque mot. Cette représentation est une combinaison des informations de tous les autres mots, pondérée par leur importance relative.
- Transformation Linéaire : La représentation combinée passe ensuite par une transformation linéaire pour produire la sortie du mécanisme d’attention (matrice Z du schéma ci-dessus).
- Normalisation & Feed-forward : Après l’attention, la sortie est normalisée et passe par un réseau feed-forward positionnel. Cela ajoute une capacité de transformation supplémentaire au modèle.
- Empilement des Couches : Plusieurs de ces mécanismes d’attention (et réseaux feed-forward) sont empilés les uns sur les autres pour former l’architecture complète du Transformer. Cela permet au modèle de capturer des relations complexes et des dépendances à différents niveaux d’abstraction.
- Décodeur (si utilisé) : Dans le cas d’une tâche de traduction, par exemple, après avoir encodé la séquence d’entrée, un décodeur est utilisé pour générer la séquence de sortie. Le décodeur utilise également l’attention, mais il se concentre à la fois sur la séquence d’entrée encodée et sur les mots précédemment générés.
Transfert learning en NLP (PLN en français😅)
Le transfert learning est une technique qui consiste à utiliser un modèle pré-entraîné sur une tâche générale et à l’adapter à une tâche spécifique. Cette technique est particulièrement utile pour les transformers, qui sont des architectures de réseaux de neurones profonds capables de traiter des séquences de données, comme le texte ou la parole. Les transformers ont révolutionné le domaine du traitement du langage naturel (PLN) en offrant des performances inégalées sur de nombreuses tâches, comme la traduction automatique, la génération de texte ou l’analyse de sentiments.
Cependant, entraîner un transformer à partir de zéro nécessite beaucoup de données et de ressources computationnelles, ce qui n’est pas toujours disponible pour les praticiens. C’est pourquoi le transfert learning est une solution efficace pour tirer parti des connaissances acquises par un transformer pré-entraîné sur un large corpus de texte, comme Wikipedia ou le web, et les transférer à une tâche plus spécifique, comme la classification de documents ou la réponse aux questions. Le transfert learning permet ainsi de réduire le temps et le coût d’entraînement, tout en améliorant la qualité des résultats. Nous allons voir dans la suite comment utiliser le transfert learning avec les transformers dans la pratique, en utilisant la bibliothèque Hugging Face, qui propose une collection de modèles pré-entraînés et d’outils pour le PLN.
Pour illustrer les différents cas d’usage, nous allons utiliser des données d’actualité sur l’internet et engagement des lecteurs (voir Internet news data with readers engagement | Kaggle) disponible sur Kaggle. Le jeu de données contient des données relatives aux actualités sur internet et ont été collectées entre Septembre et le Novembre 2019. Les données contiennent des articles (classés en tête de liste en termes de popularité sur le site web de l’éditeur) provenant de plusieurs éditeurs bien connus. Ensuite, à l’aide de Facebook GraphAPI, les données ont été enrichies avec des caractéristiques d’engagement telles que les partages, les réactions et le nombre de commentaires.
Ci-dessous on donne quelques informations sur les colonnes:
- Source_id: indique l’identifiant unique de l’éditeur, généralement présenté sous la forme d’un nom de source en minuscules, les espaces étant remplacés par le symbole du trait de soulignement.
- Source_name: indique le nom de l’éditeur.
- Author: indique l’auteur de l’article. Certains éditeurs ne partagent pas d’informations sur les auteurs de leurs nouvelles. Dans ce cas, le nom de la source remplace généralement cette information.
- Title: indique le titre de l’article.
- Description: indique une brève description de l’article, généralement visible dans les fenêtres contextuelles ou les boîtes de recommandation sur le site web de l’éditeur. Ce champ est raccourci à quelques phrases dans la colonne Contenu.
- Url: indique l’URL (Uniform Resource Locator) de l’article sur le site web de l’éditeur.
- Url_to_image: indique l’URL de l’image principale associée à l’article.
- Published_at: indique la date et l’heure exactes de la publication de l’article. La date et l’heure sont présentées au format UTC (+000).
- Content: indique le contenu non formaté de l’article. Ce champ est tronqué à 260 caractères.
- Top_article: indique que l’article figure en tête de liste sur le site web de l’éditeur. Ce champ ne peut avoir que deux valeurs : 1 lorsque l’article est contenu dans le groupe des articles populaires/de tête et 0 dans le cas contraire.
Introduction de Hugging Face Transformers

Hugging Face est une communauté d’IA et une plateforme de Machine Learning créée en 2016 par Julien Chaumond, Clément Delangue, et Thomas Wolf. Elle vise à démocratiser le NLP en fournissant aux Data Scientists, aux praticiens de l’IA et aux ingénieurs un accès immédiat à plus de 10 000 modèles pré-entraînés basés sur l’architecture de transformers à la pointe de la technologie. Ces modèles peuvent par exemple être appliqués à :
- Du texte dans plus de 100 langues pour effectuer des tâches telles que la classification, l’extraction d’informations, la réponse à des questions, la génération et la traduction.
- La parole, pour des tâches telles que la classification audio d’objets et la reconnaissance vocale.
- La vision pour la détection d’objets, la classification d’images, la segmentation.
- Données tabulaires pour les problèmes de régression et de classification.
Hugging Face Transformers fournit également près de 2000 ensembles de données et des API en couches, permettant aux programmeurs d’interagir facilement avec ces modèles à l’aide de près de plusieurs bibliothèques. La plupart d’entre elles s’appuient sur des frameworks tels que Pytorch et Tensorflow. Hugging Face offre également une plateforme collaborative nommée Spaces, qui permet aux utilisateurs de partager et d’expérimenter avec leurs propres modèles de langage.
Hugging Face est donc une plateforme incontournable pour tous les passionnés et les professionnels du traitement du langage naturel, qui souhaitent bénéficier des dernières avancées technologiques dans ce domaine.
Utilisation de Hugging Face pour de la traduction:
La traduction est peut-être l’une des tâches les plus courante en NLP. Si l’on est habitué aux outils tels que Google traduction, il est beaucoup plus challengeant de réaliser de la traduction de manière automatique depuis un environnement de développement tel que Jupyter Notebook. Avec Hugging face, il suffit de suivre les étapes ci-dessous:
- Chargement d’un tokenizer et d’un modèle
# chargement des librairies
from transformers import MarianTokenizer, MarianMTModel
import torch
# Nom du modèle
model_name = 'Helsinki-NLP/opus-mt-en-fr'
# Création le Tokenizer
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Création du modèle
model = MarianMTModel.from_pretrained(model_name)Le chargement du modèle peut prendre quelques minutes car la bibliothèque Hugging face va télécharger les modèles en local.
- Utilisation du Tokenizer et du modèle pour réaliser la traduction
def format_batch_texts(language_code, batch_texts):
"""
Format the batch texts for the model
"""
formated_bach = [">>{}<< {}".format(language_code, text) for text in batch_texts]
return formated_bach
def perform_translation(batch_texts, model, tokenizer, language="fr"):
"""
Perform the translation
"""
# Prepare the text data into appropriate format for the model
formated_batch_texts = format_batch_texts(language, batch_texts)
# Generate translation using model
translated = model.generate(**tokenizer(formated_batch_texts, return_tensors="pt", padding=True))
# Convert the generated tokens indices back into text
translated_texts = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
return translated_texts
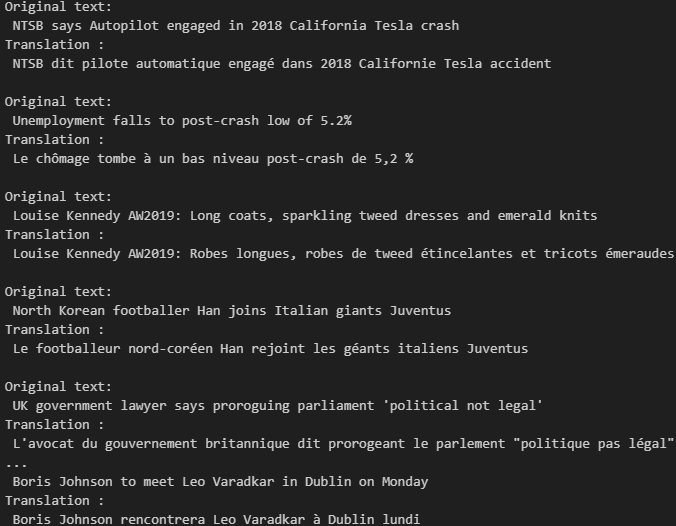
# Check the model translation from the original language (English) to French
english_texts = news_data["title"]
trans_model = model
trans_model_tkn = tokenizer
translated_texts = perform_translation(english_texts[0:10], trans_model, trans_model_tkn)
for orig_text, trans_text in zip(english_texts, translated_texts):
print("Original text: \n", orig_text)
print("Translation : \n", trans_text)
print("")On obtient le résultat ci-dessous:
Classification sans exemple (ou zero-shot learning)
La classification zéro shot est une technique de traitement du langage naturel qui permet à un modèle d’apprendre à classer des exemples de classes non vues pendant l’entraînement. Cette méthode est basée sur l’utilisation d’un modèle de langage pré-entraîné et peut être considérée comme une instance de transfert d’apprentissage qui consiste généralement à utiliser un modèle entraîné pour une tâche dans une application différente de celle pour laquelle il a été initialement entraîné.
La classification zéro shot est particulièrement utile dans des domaines comme la reconnaissance d’objets, où il peut y avoir des milliers de classes et où il est impraticable d’obtenir des données d’entraînement pour chacune d’entre elles.
Ci-dessous un exemple de comment cela fonctionne en pratique:
- Représentation sémantique: Chaque classe (qu’elle soit vue ou non pendant l’entraînement) est associée à une représentation sémantique. Cette représentation peut être, par exemple, un vecteur d’attributs (où chaque attribut pourrait être “a des ailes”, “vole”, “est vert”, etc.) ou un vecteur dans un espace de mot incorporé (comme word2vec ou GloVe).
- Phase d’entraînement: Pendant l’entraînement, le modèle apprend à associer les entrées (comme des images) à ces représentations sémantiques plutôt qu’à des étiquettes de classe directes.
- Phase de test: Lors de la classification d’un nouvel objet appartenant à une classe jamais vue pendant l’entraînement, on utilise sa représentation sémantique pour déterminer à quelle classe il appartient. Le modèle, ayant appris à associer des entrées à des représentations sémantiques, peut maintenant “deviner” la classe d’un objet en trouvant la représentation sémantique la plus proche de la sortie du modèle pour cette entrée.
Il existe plusieurs variantes et extensions de l’apprentissage zéro shot, notamment :
- Apprentissage à un coup (“one-shot learning”): Le modèle voit chaque classe pendant l’entraînement, mais seulement avec très peu d’exemples.
- Apprentissage à quelques coups (“few-shot learning”): Le modèle est entraîné avec un petit nombre d’exemples pour chaque classe.
- Apprentissage zéro shot généralisé: Le modèle est testé à la fois sur des classes vues et non vues pendant l’entraînement.
Dans l’exemple ci-dessous, on va réaliser un exemple simple de classification sans exemple. Comme précédemment, il est nécessaire d’instancier un Pipeline en spécifiant la tâche que l’on souhaite mettre en place et le modèle que l’on souhaite utiliser.
# defining functions
def classify_text(text, candidate_labels):
# load the pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
# classify the text
prediction = classifier(text, candidate_labels)
return prediction
def print_classification_result(prediction):
print("\n la phrase utilisée: ", prediction['sequence'])
print("\n les scores de classification zéro-shot:")
display(pd.DataFrame(prediction).drop(["sequence"], axis=1))
# list candidates labels
candidate_labels = ["tech", "politics", "business", "finance"]
# example text
english_text = english_texts[0]
# classify the text and print the result
prediction = classify_text(english_text, candidate_labels)
print_classification_result(prediction)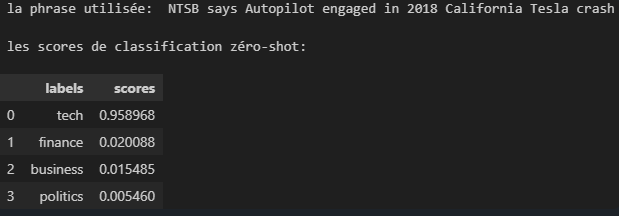
Analyse de sentiments.
La plupart des modèles de classification des sentiments nécessitent un entraînement préalable. Le module hugging Face pipeline facilite l'exécution des prédictions d'analyse des sentiments en utilisant des modèles spécifiques disponibles directement sur le hub. Vous pouvez avoir la liste de tous les modèles en visitant le lien ci-contre: Models - Hugging Face.
Ici on va utiliser le modèle distilbert-base-uncased-finetuned-sst-2-english avec le code ci-dessous:
# model selection
model_checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
# model pipeline
distil_bert_model = pipeline(task="sentiment-analysis", model=model_checkpoint)
# display the whole column with pandas
pd.set_option("display.max_colwidth", None)
sentence_list = english_texts[:10].tolist()
sentiment = []
score = []
for sentence in tqdm(sentence_list):
result = distil_bert_model(sentence)
sentiment.append(result[0]['label'])
score.append(result[0]['score'])
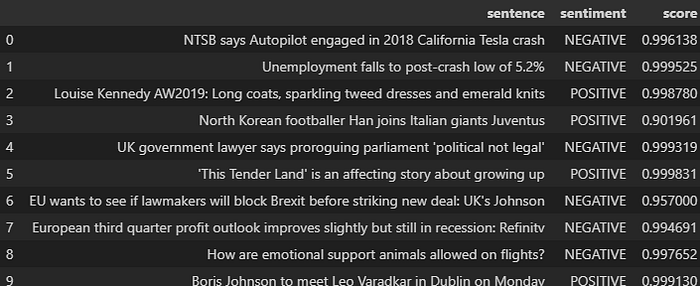
pd.DataFrame({"sentence": sentence_list,"sentiment": sentiment, "score": score})On obtient le résultat ci-dessous:
Question answering (Q&A):
La tâche de question answering (QA) en NLP consiste à répondre à des questions formulées en langage naturel à partir d’un texte source. Par exemple, si le texte source est un article de Wikipédia sur la France, et la question est “Quelle est la capitale de la France ?”, la réponse attendue est “Paris”.
Pour réaliser cette tâche, il faut être capable d’analyser la question, de comprendre le texte source, et de générer ou d’extraire la réponse pertinente. Hugging Face propose des modèles pré-entraînés et des outils pour faciliter le développement et le déploiement de systèmes de QA. Avec Hugging Face, on peut utiliser des modèles comme BERT, ALBERT ou DistilBERT pour créer des systèmes de QA performants et adaptés à différents domaines.
Le code ci-dessous, illustre un cas d’usage avec le modèle deepset/roberta-base-squad2.
# specify the model
model_checkpoint = "deepset/roberta-base-squad2"
# specify the task
task = 'question-answering'
# instantiate the pipeline
QA_model = pipeline(task, model=model_checkpoint, tokenizer=model_checkpoint)On considère la phrase ci-dessous:
'A top Pakistani health official says authorities are battling one of the '
'worst-ever dengue fever outbreaks in the country, including the capital '
'Islamabad as hospitals continued to receive scores of patients, putting '
'strain on emergency services.En utilisant le fonctions définis précédemment, et la phrase ci-dessus comme élément de contexte on peut alors poser des questions. Le code ci-dessous présente comment réaliser cette tâche avec Python.
# Q&A function
def get_model_response(question, context):
QA_input = {
'question': question,
'context': context
}
model_response = QA_model(QA_input)
return pd.DataFrame([model_response])
# Usage:
question = 'what is the capital of Pakistan?'
context = text_sample
result = get_model_response(question, context)
resultOn obtient le résultat ci-dessous:

Conclusion
Les transformers sont des modèles puissants et flexibles qui permettent de traiter des données séquentielles de manière efficace et innovante. Ils sont à la base de nombreuses applications de traitement du langage naturel, comme la génération de texte, la traduction automatique, la compréhension de texte, etc.
Hugging Face est une entreprise qui propose des outils et des ressources pour faciliter l’utilisation et le développement des transformers. Grâce à sa bibliothèque Transformers, sa plateforme Datasets, son hub de modèles et ses espaces collaboratifs, Hugging Face rend les transformers accessibles à tous les niveaux d’expertise et encourage la recherche et l’innovation dans le domaine du NLP. Si vous souhaitez en savoir plus sur les transformers et Hugging Face, vous pouvez consulter leur site web, leur documentation et leur blog.
Vous pouvez retrouver le notebook avec tout le code ci-dessus sur transformers_hugging_face/notebook/hugging_face.ipynb at master · ssime-git/transformers_hugging_face (github.com)
